Purpose of the article
This article specifies how to create a regular expression and it provides the most frequent syntaxes.
References and test
The website https://regex101.com provides many resources and a powerful tool to analyze your regular expressions online.
Regular expression basics
A regular expression consists of symbols that specify the rules that apply to the extraction of information in a string.
Characters
The following symbols represent a character:
- [a-c]: an alphabetic character between a and c, lowercase / [A-C]: an alphabetic character between A and C, uppercase
- [a-zA-Z]: an alphabetic character between a and z, lowercase or uppercase
- [0-5]: a number between 0 and 5
- [^a-z]: the hat ^ is an inversion operator. This means that the character is anything but between a and z, lowercase
- [-_]: either a dash or underscore character (underscore)
- The dot represents any character
Rehearsals
The following symbols specify the rules for repeating characters:
- a*: the asterisk allows an unlimited number of repetitions of character a
- a+: checks for the presence of one or more a characters
- s? : checks for zero or one character a
- (...)? : checks for the presence of no or one capture group
- a{3} or a{3,3}: exactly three repetitions of character a
- [a-zA-Z]{3,1}: three or more repetitions of characters between a and z, lowercase or uppercase.
- [0-1]{3,6}: between three and six repetitions of a digit between 0 and 1
Conditions
- ^ : placed at the beginning of the expression, it indicates the beginning of the string. This means that it forces the expression to evaluate successfully from the first character.
- $ : placed at the end of the expression, it indicates the end of the string. This means that it forces the expression to evaluate successfully down to the last character.
- (...) : parentheses are used to create an expression capture group
- (?:...) : captures everything that is part of the group
- (?<name>...) : Named expression capture group. In Cooperlink, the use of a field's key allows it to be identified with the field concerned. If the group refers to a field of type list of values, its capture must be one of the values encoded in Cooperlink to be successfully extracted.
Example
Filename with structure [code]-[title]-[revision]
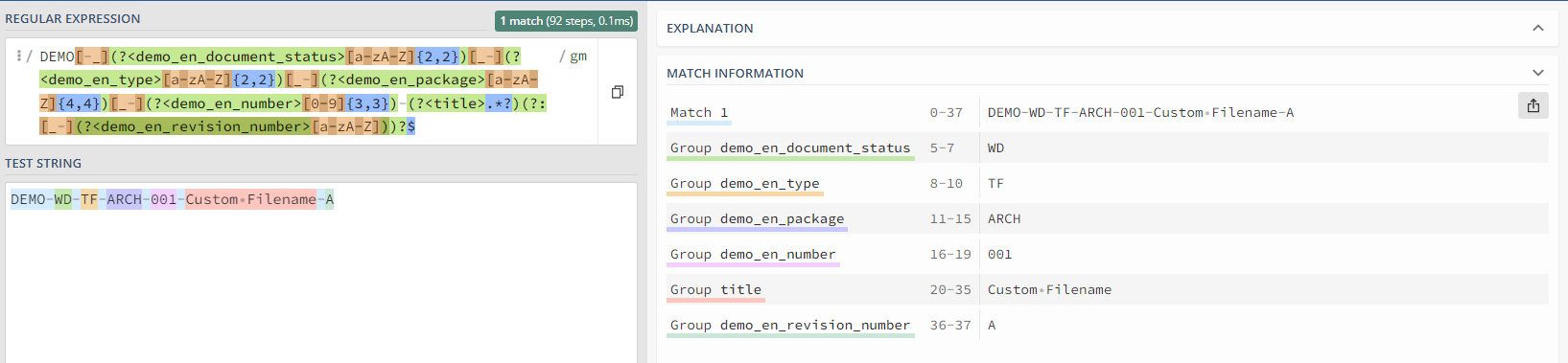
Let's decode the following regular expression with the structure [CODE]-[TITLE]-[REVISION]:
DEMO[-_](?<demo_en_document_status>[a-zA-Z]{2,2})[_-](?<demo_en_type>[a-zA-Z]{2,2})[_-](?<demo_en_package>[a-zA-Z]{4,4})[_-](?<demo_en_number>[0-9]{3,3})-(?<title>.*?)(?:[_-](?<demo_en_revision_number>[a-zA-Z]))?$The character string is evaluated as follows:
- It must start with DEMO
- Then followed by a dash or underscore (underscore)
- The following characters must be alphabetic, 2 in number, lowercase or uppercase. These 2 letters will be captured in group demo_en_document_status. Within Cooperlink, in case of a list of values, the 2-character code extracted must be one of the values encoded in the configuration of the field.
- Then followed by a dash or underscore (underscore)
- The following characters must be alphabetic, 2 in number, lowercase or uppercase (group demo_en_type).
- Then followed by a dash or underscore (underscore)
- The following characters must be alphabetic, 4 in number, lowercase or uppercase (group demo_en_package).
- Then followed by a dash or underscore (underscore)
- The following characters must be numeric, 3 in number (groupdemo_en_number)
- Then followed by a dash
- An indeterminate string is then captured in a titlegroup . The asterisk guarantees the positive evaluation of the expression until the last character following the presence of the $ character at the end of the string.
- A single alphabetic character, lowercase or uppercase, is optionally present at the end of the string, and preceded by a dash or underscore. This is captured as a revision index in group demo_en_revision_number.
Excerpt from regex101